
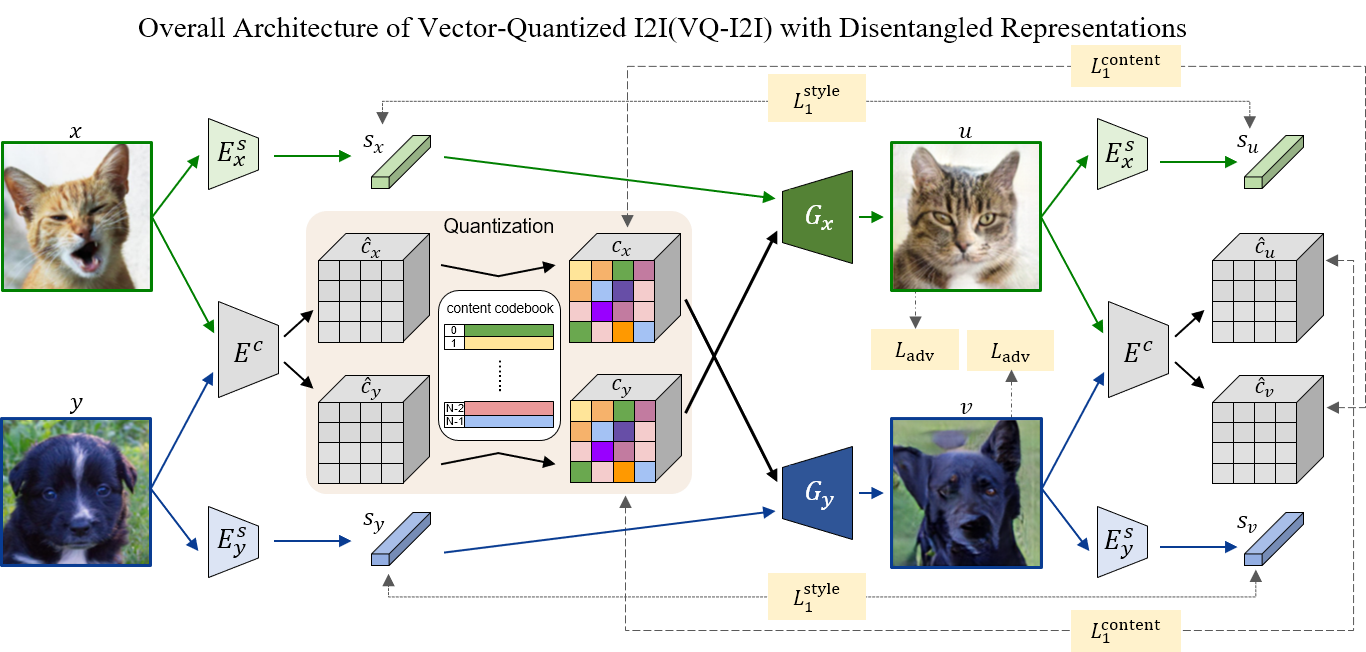
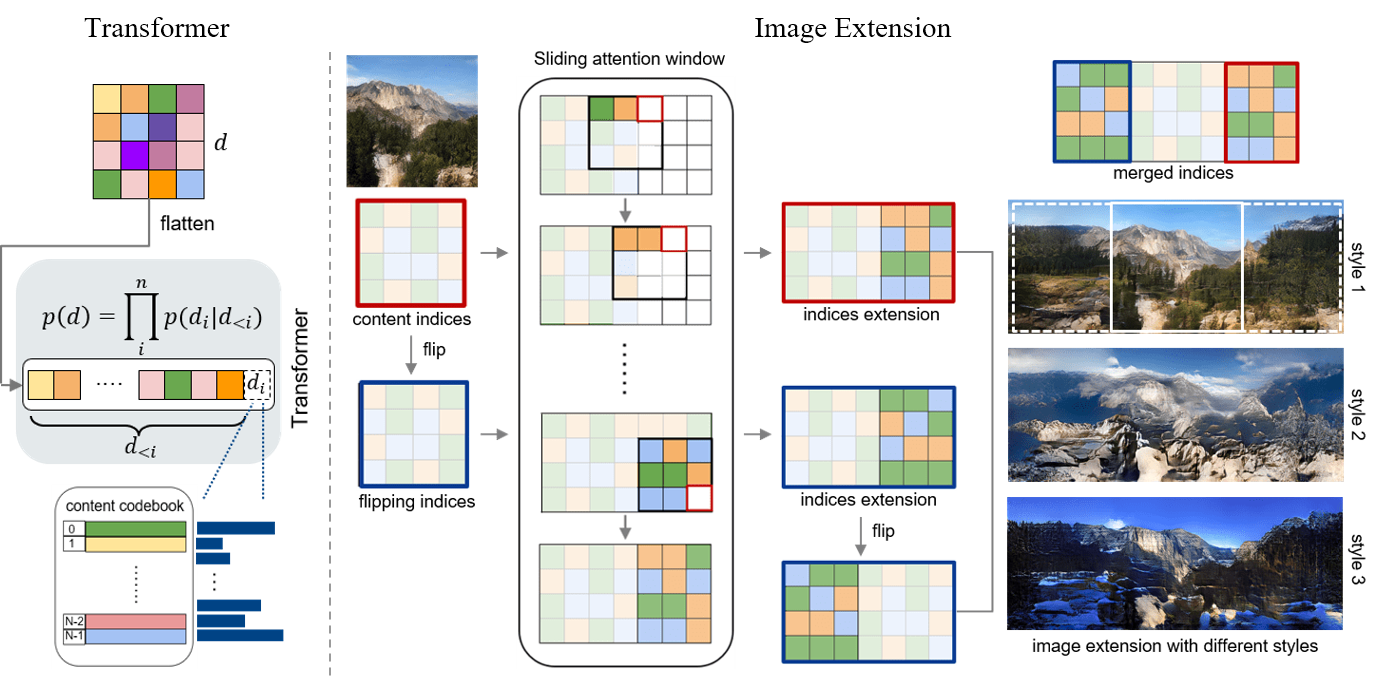
Current image-to-image translation methods formulate the task with conditional generation models, leading to learning only the recolorization or regional changes as being constrained by the rich structural information provided by the conditional contexts. In this work, we propose introducing the vector quantization technique into the image-to-image translation framework. The vector quantized content representation can facilitate not only the translation, but also the unconditional distribution shared among different domains. Meanwhile, along with the disentangled style representation, the proposed method further enables the capability of image extension with flexibility in both intra- and inter-domains. Qualitative and quantitative experiments demonstrate that our framework achieves comparable performance to the state-of-the-art image-to-image translation and image extension methods. Compared to methods for individual tasks, the proposed method, as a unified framework, unleashes various applications combining image-to-image translation, unconditional generation, and image extension altogether. For example, it provides style variability for image generation and extension, and equips image-to-image translation with further extension capabilities.
@inproceedings{chen2022eccv,
title = {Vector Quantized Image-to-Image Translation},
author = {Yu-Jie Chen and Shin-I Cheng and Wei-Chen Chiu and Hung-Yu Tseng and Hsin-Ying Lee},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}